How we structure design systems to be read by AI
Francois Brill
Designer + Builder

An AI-ready design system is a project's source of truth structured so AI coding tools read the same conventions on every session. It pairs the visual styleguide humans rely on with token files, component spec stubs, and machine-readable documentation that survive the context window resetting between sessions.
The diagram that changed how I think about design systems
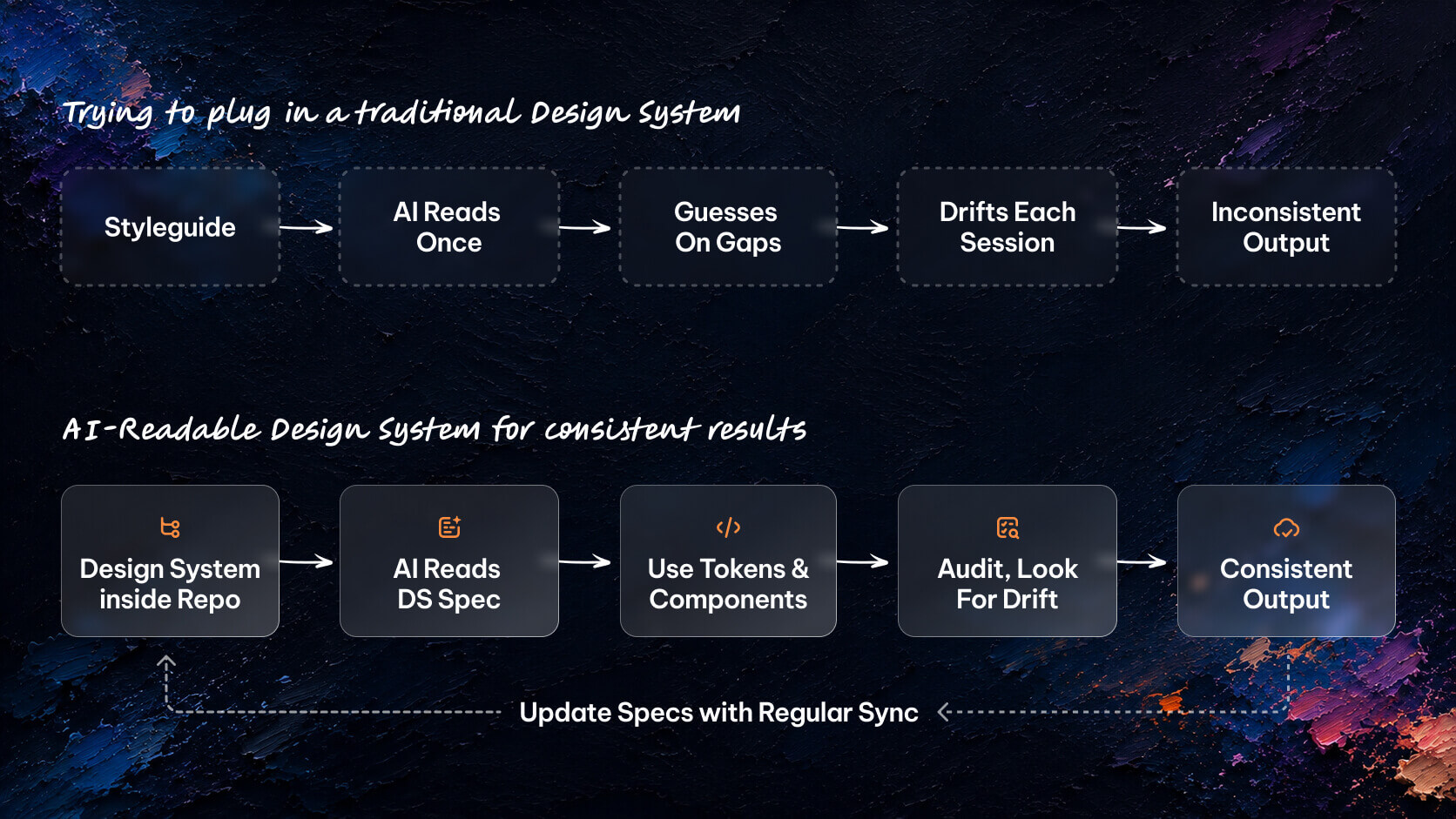
Two flows. Side by side.
The first: traditional styleguide. Someone writes the spec. Developers get the Notion doc, the PDF, the Confluence page. Components get built. The styleguide sits there. The codebase drifts. Three months later, the spec says one thing and the code says another. Nobody updates the PDF.
The second: LLM-readable spec. Tokens and component contracts live in the repo, version-controlled, loadable on demand. The AI tool reads the spec at session start. Components get built to spec. Drift surfaces as an audit failure, not as a design review three months too late.
I've seen variations of this framing in public conversation for well over a year. What the diagram did was crystallize it. Two flows. One drifts invisibly. One makes drift auditable.
I already knew our design systems drifted. Most do. What I hadn't fully articulated was why AI makes it worse, and what the actual fix looks like.
Drift is older than AI
Brad Frost published Atomic Design in 2013. The core insight was right: build components bottom-up, document them, give your team a shared vocabulary. Every design system methodology since has operated on the same premise.
The cycle that followed was predictable. Six weeks writing the styleguide. Devs start building. Six months in, the styleguide is twelve pages of PDF that nobody opens.
Tokens defined in Figma diverge from code. Component names in Storybook don't match what the codebase calls them. Designers say "primary." Devs ship a button backed by --color-cta. Both are right in their own context. Neither matches the spec.
Most teams' design systems are already drifting. It's just been polite to pretend otherwise.
“Design systems were always drifting. AI just made the drift impossible to ignore.
We had this problem too. Multiple times, across multiple projects. We just didn't have a sharp enough lens to see all the fault lines at once.
Why AI sessions make it loud
Claude, Cursor, Copilot. They're all stateless.
Each session starts fresh. No memory of last week's token rename. No record that accent-deep replaced primary-500 in that refactor two sprints ago. The AI picks up the codebase as-is and infers the rest.
Two things happen. First, the AI re-derives your design system from whatever it can read. Usually tailwind.config.js, maybe a few sample components. Second, when sources contradict (and they always do), the AI picks one. Sometimes right. Sometimes not.
Example: In a Cursor session on a Vue/Nuxt project, we asked Claude to add a new marketing section matching our brand colors. Claude returned a component using primary-500 throughout. Confident, syntactically correct. The problem: primary-500 doesn't exist in our project. Our actual token is accent-deep, a custom name tied to a specific hex value that went through rounds of brand review. Claude had no way to know that. It defaulted to the generic naming convention it's seen across thousands of training examples. The output compiled. It shipped the wrong color.
That's not a Claude failure. That's a documentation failure.
We'd also tried earlier workarounds. "Describe the design in chat" worked for one component, then broke down completely once a project had ten components with interdependencies. Storybook seemed like a promising source of truth: great for designers browsing, terrible for AI. Components are scattered. The design system is implicit in what got staged. Nothing is structured for machine reading. Figma tokens were useful on the design side and mostly invisible to code. Three drift points instead of one.
A design system that ships as a static PDF is a design system an AI tool can't keep up with.
The fix isn't better prompts. It's a better source of truth.
“Stateless sessions need stateful documentation.
What "LLM-readable" means in practice
The phrase sounds complicated. It isn't.
"LLM-readable" is just well-structured documentation an AI can load on demand. Plain text, version-controlled, organized by tier. That's it.
Compare a typical starting point with where we land. Most projects we inherit look something like this: a config file, a handful of components, no spec.
// tailwind.config.js
module.exports = {
theme: {
extend: {
colors: {
primary: "#1d4ed8",
accent: "#f59e0b",
"accent-deep": "#b45309",
},
fontFamily: {
sans: ["Inter", "sans-serif"],
},
},
},
}A few color values in an extend block. Maybe a font. The AI reads this, infers a design system, and fills the gaps with its best guess. When the guesses compound across a whole component, output drifts.
Our current structure:
app/design-system/
├── DESIGN.md ← single source of truth
├── tokens.css ← runtime CSS variables
├── tokens.json ← W3C DTCG export
├── copywriting.md ← voice rules
└── specs/
├── foundations/
├── tokens/
├── atoms/
├── molecules/
└── organisms/Each file has one job. tokens.css wires CSS variables to actual hex values. tokens.json exports the same tokens in W3C DTCG format for Figma and other tooling. copywriting.md holds voice and tone rules. The specs/ directory holds component contracts, organized by tier.
The constraint that matters: both Tailwind utilities and CSS custom properties resolve to the same hex value. One token. Two surfaces. No drift between them.
Articles 3 and 4 go deep on the wiring. For now, the point is that this structure is opinionated but the idea is generic. Any text-readable, version-controlled, tier-structured design system achieves the same goal. The specific format matters less than the discipline.
Why purpose-built beats one big file
This is where most teams get it wrong, including us.
When you realize a styleguide isn't enough, the instinct is to write a bigger styleguide. One canonical document. All specs in sequence. Everything in one place.
We tried it. A single DESIGN.md with tokens, component specs, voice rules, and layout conventions, all in order. It worked for trivial tasks. For real work, it collapsed.
Claude would correctly reference a color value from line 40 and miss the voice rule on line 340. Same failure as the twelve-page PDF, but in one file. The AI read the top half. The bottom half drifted.
The CLAUDE.md trap followed the same pattern. We stuffed it with more: token references, conventions, voice rules. It got too long. The AI only partially read it. It became another drift-prone document, just in version control instead of a shared drive.
“CLAUDE.md is a manifesto. A design system is a contract.
A single big file leaves gaps. Places where AI must guess. Every gap is a drift entry point. The fix isn't a bigger file. It's tiered, purpose-built structure where each file has one job and the relationships between them are explicit.
Foundations describe intent. Tokens describe vocabulary. Specs describe contracts. Nothing important lives in a paragraph the AI has to find by accident.
This structure doesn't just help AI. It helps everyone who reads the system.
The clarity that makes Claude consistent makes new hires consistent. Designers reading copywriting.md know the voice rules without digging through five hundred lines of DESIGN.md. Engineers tracing accent-deep to its hex value follow tokens.css in under a minute. One source of truth. Four different audiences: AI tools, designers, engineers, whoever onboards next quarter.
That's where the real value is. The AI consistency is a forcing function. The human consistency is the payoff.
How we build design systems now
The underlying ideas here are not new. Atomic design: 2013. LLM-readable documentation has been a public conversation for well over a year. We didn't invent this. What we settled on is a specific structure where every piece earned its place through real work on real client projects.
The projects: marketing websites and product apps. Different stacks. Vue/Nuxt with Tailwind v4, React with Next.js. Same structure each time. Each project sharpened it.
Two iterations stand out.
On one marketing project, AI-generated copy kept sounding generic. Correct brand colors, right component structure, wrong voice. Too formal. Flat. We had no voice spec for Claude to read, so it defaulted to average. We added copywriting.md after that project: tone principles, vocabulary preferences, what to avoid. On the next project, copy came back on-brand without extra prompting.
On an earlier product project, Claude kept reaching for the wrong spacing scale. Foundations and tokens were collapsed into a single file. Claude was pulling values from the middle of the document and inferring a scale that half-matched ours. Separating foundations from tokens fixed it. Foundations describe intent. Tokens describe the specific values that implement that intent. Claude stopped guessing.
The one-big-file failure: we hit it twice before we split the monolithic CLAUDE.md. Once on a marketing project. Once on a product app. After the second time, we split the structure. Output quality stepped up noticeably.
The structure has stabilized enough that we scaffold it the same way at the start of every new project. Article 7 covers how we packaged it as a reusable Claude Code skill.
The compounding principle: each project surfaces a new constraint. We capture it, refine the spec, and the next project starts sharper. The documentation that powers AI is itself iterated by the work it does. It doesn't plateau. It gets sharper.
What's in this series
- The methodology (Article 2): the tier structure, the spec format, and why it works for AI and humans alike
- The audit step (Article 3): meeting existing projects where they are, before rebuilding anything
- The wiring (Article 4): tokens.css plus Tailwind v4
@theme, and what we got wrong the first time - Writing specs that work as prompts (Article 5): how to write component specs that AI treats as instructions, not suggestions
- The reconciliation (Article 6): what to do when the design system and the codebase disagree
- Packaging it (Article 7): turning this into a reusable Claude skill anyone can run on their own project
What this isn't
Not a Tailwind v4 tutorial. Not an atomic design history lesson. Not an AI tool comparison.
One clarification worth making explicit: this series is about making a design system readable by AI tools. It's not about designing AI product features, which is the separate Designing for AI series.
The structure compounds
More stateful documentation means more predictable AI output. Not marginally more. Noticeably more, in ways that show up in client reviews and in the time spent correcting generated components.
The fix is the same one it's always been for design systems: be specific, document the decisions, keep the spec and the code in sync. AI just makes the cost of not doing it immediate rather than something you notice six months later in a design review.
Article 2 covers the full structure: what each tier holds, how the files relate, and what a component spec looks like when it works as a source of truth for both people and tools.
Frequently asked questions
What is an AI-ready design system?
How is an AI-ready design system different from a regular design system?
Why do AI coding tools need a structured design system?
What's in an AI-ready design system?
Do you need to rewrite your existing design system to make it AI-ready?
About the author

Francois Brill
Designer + Builder, Clearly Design, Inc.
Francois has been designing and shipping software products since 2002, with a focus on the messy middle between design and the codebases that consume them. He runs Clearly Design, a product design subscription studio for SaaS founders, and writes about how design systems hold up under AI-assisted development.
